面试题总结
面试题目总结
1. Java-算法
1.1 & 运算符
1 | 1. // &是是针对二进制的二目运算符。需要注意的是&&是java中判断条件之间表示“和”的标识符,&是一个二目运算符, |
2. mysql底层索引存储原理
3. 数据库-事务
事务是一组操作的集合,这组操作,要么全部执行成功,要么全部执行失败。
mysql的事务默认是自动提交,一条语句执行之后就自动提交了
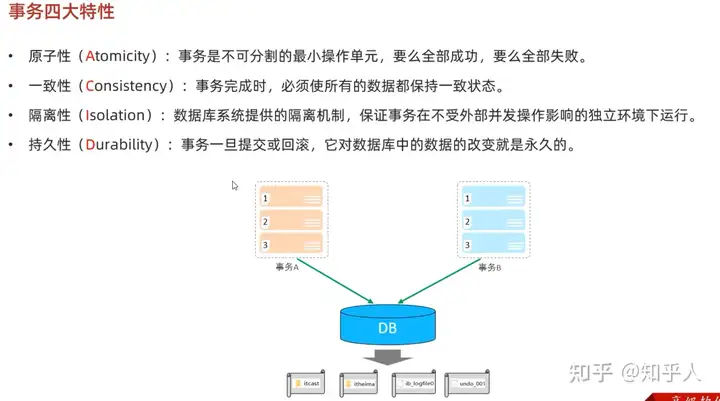
3.1 事务的四大特性
- 原子性
- 一致性
- 隔离性
- 持久性
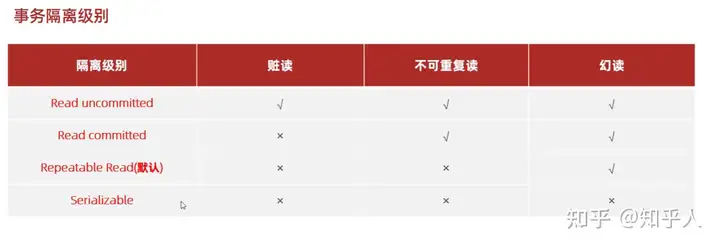
3.2 并发事务问题
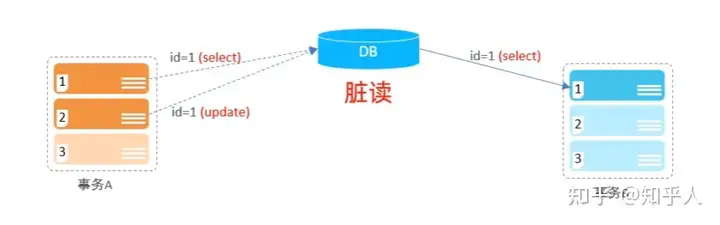
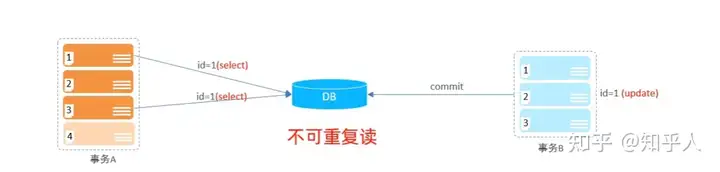
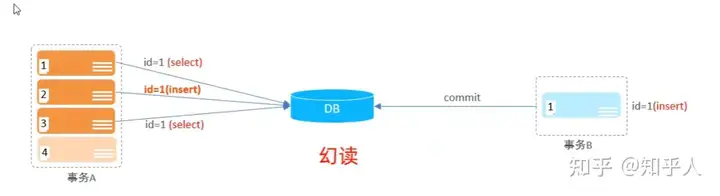
多个并发事务在执行的过程当中出现的问题
- 脏读
- 不可重复读
- 幻读

3.2.1 如何解决
通过事务不同的隔离级别进行解决(级别越高数据越安全、但效率越低)
4. 数据库-存储引擎
4.1 mysql的四大体系结构

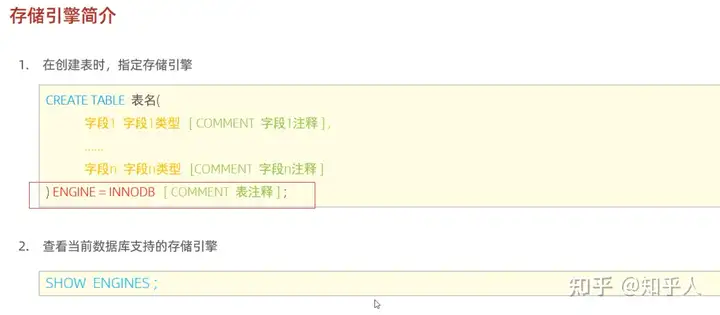
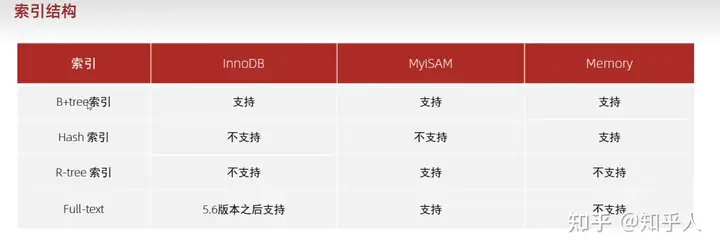
4.2 mysql的存储引擎
1 | 1. 存储引擎是基于表的,一个数据库下的不同表,可以有不同的存储引擎 |
- 如何使用
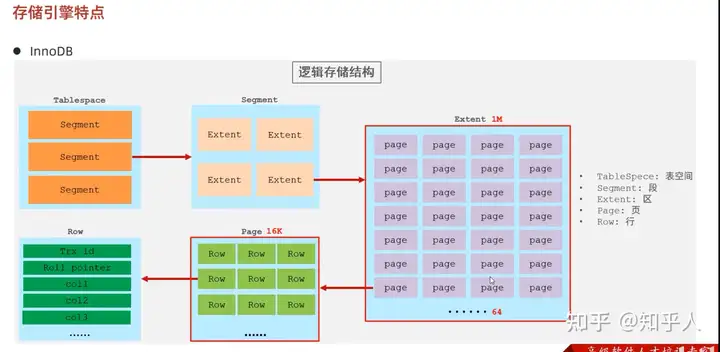
4.3 存储引擎的主要特点



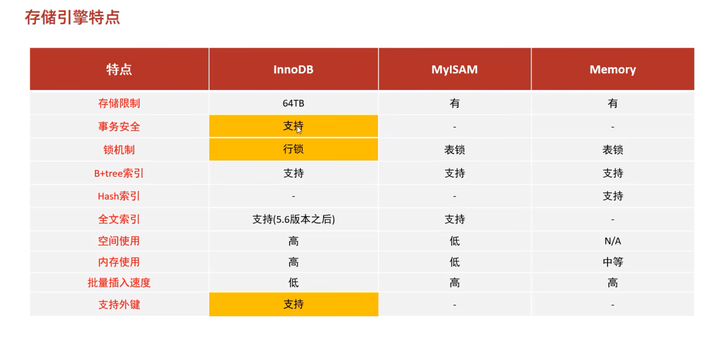
4. 4 面试题:InnoDB和MyISAM区别
问InnoDB和MyISAM的区别?(两个存储引擎的区别)
1 | InnoDB:支持事务、行锁、支持外键 |
4.5 存储引擎如何选择
1 | 根据系统应用特点,选择合适的存储引擎,一般用第一个,两外两个现在一般被MongoDB、redis代替 |

4.6 总结

5. 数据库-索引
5.1 索引概述

优缺点

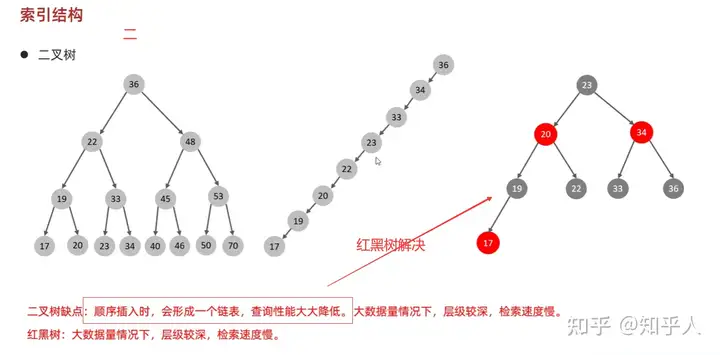
5.2 索引结构-B+树

- 二叉树(二叉搜索树)和红黑树(自平衡的二叉搜索树)
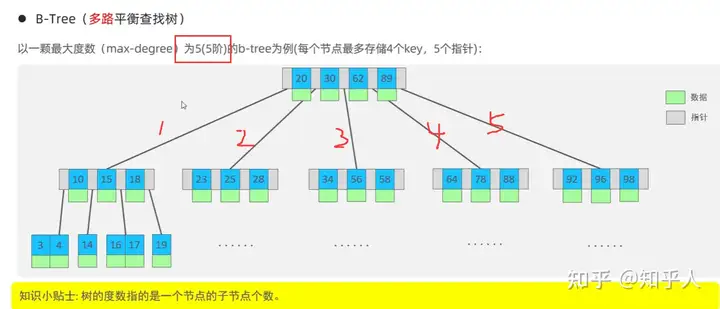
- B树(多路平衡搜索树)
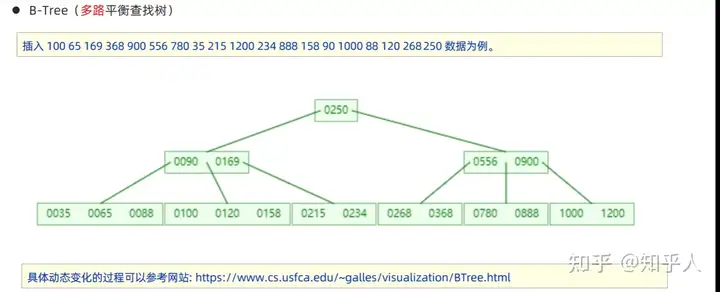
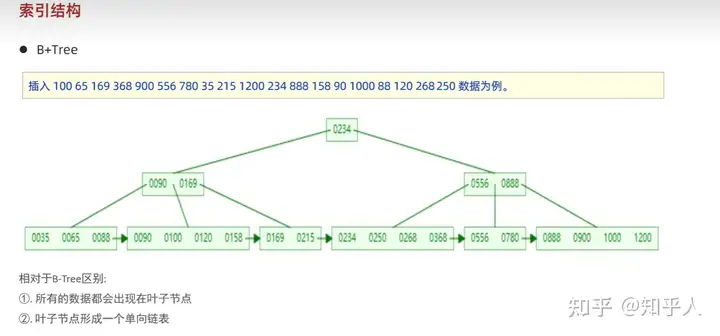
- mysql中优化后的B+树
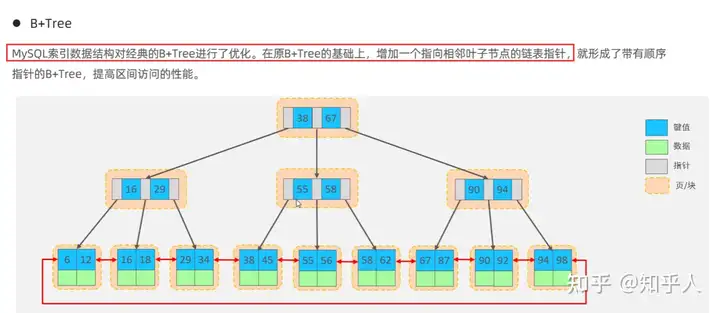
5.3 索引结构-Hash索引
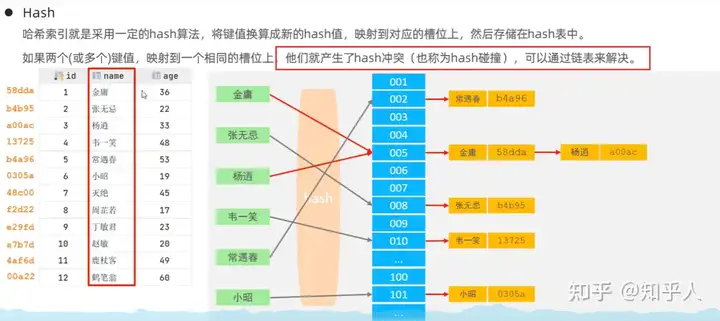

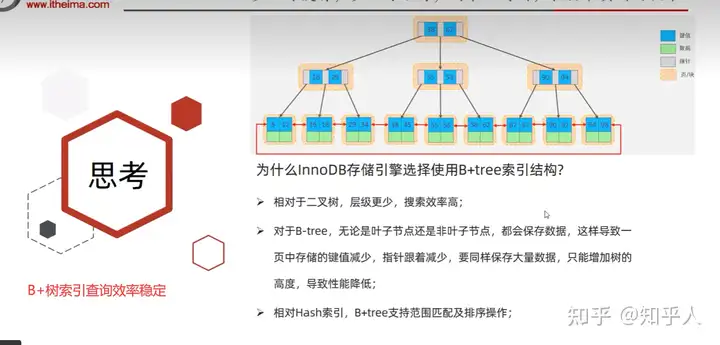
5.4 面试题:存储引擎为啥B+树
5.5 索引分类
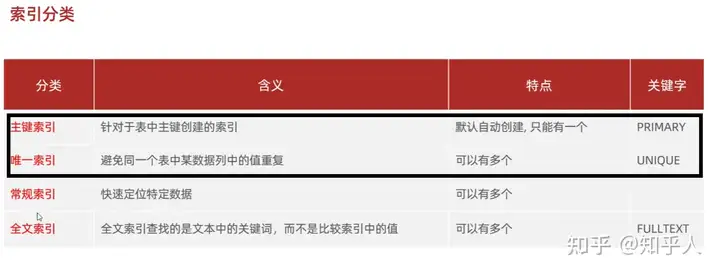

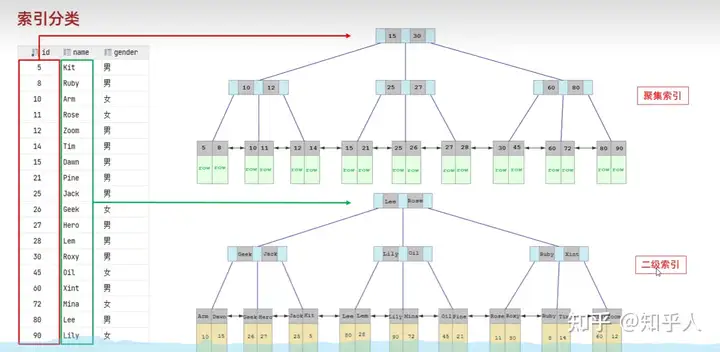
- 举例使用-回表查询
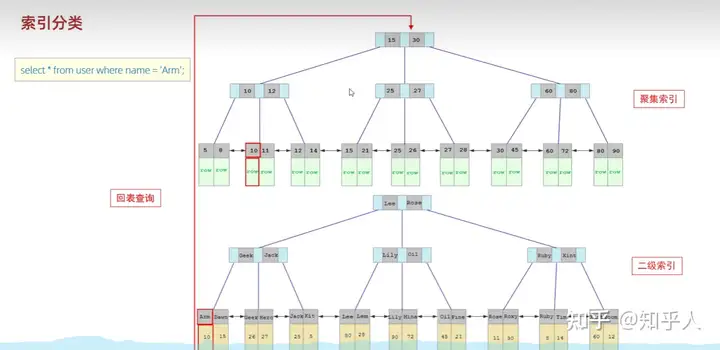
5.6 索引的使用
1. 创建索引
1 | -- 创建索引 : |
2. 查看索引
1 | -- 查看索引 |
3. 删除索引
1 | -- 删除索引 |
4. 索引小案例
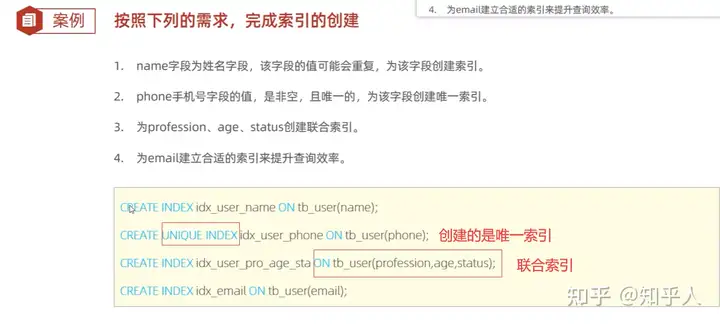
5.7 Sql性能分析
1 | -- 1. sql执行频率 |
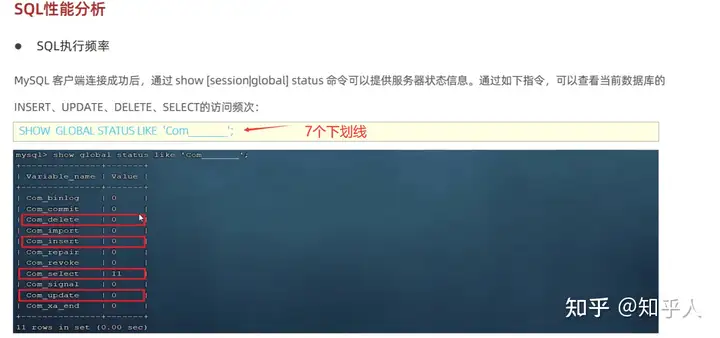

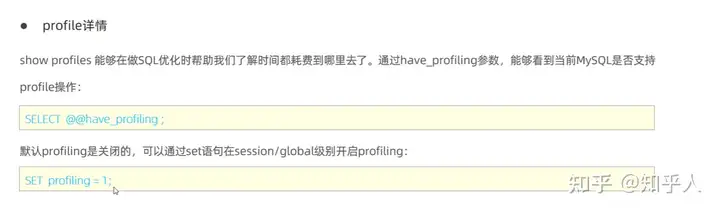
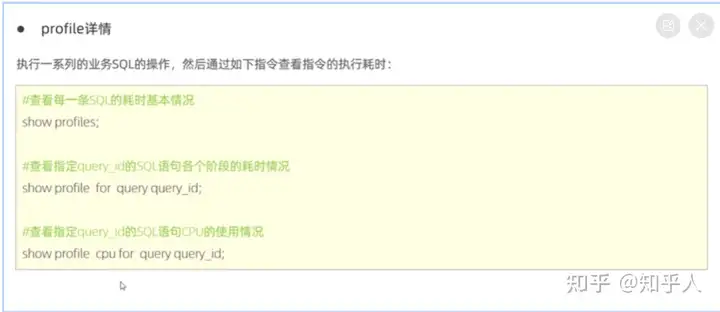
explain的相关使用和优化点



5.8 索引使用的特殊情况
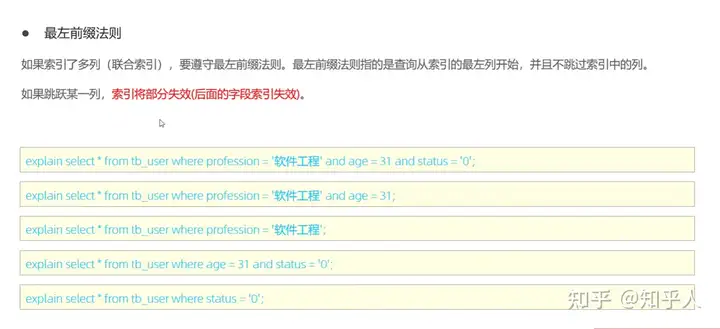

索引失效的几种情况:

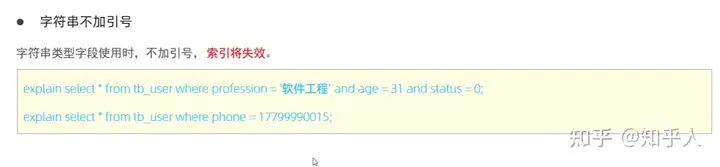
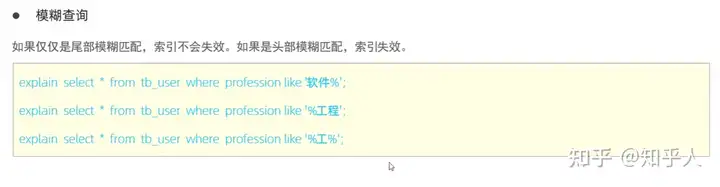
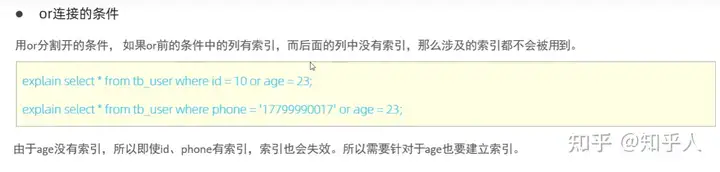

1. 面试真题
1 | 5月28日-大数据开发 |
- Title: 面试题总结
- Author: Mr.zh
- Created at : 2024-04-19 11:01:58
- Updated at : 2024-05-29 14:40:30
- Link: https://github.com/zhyoulove/2024/04/19/面试题总结/
- License: This work is licensed under CC BY-NC-SA 4.0.