数仓项目
1 | 那就停下来吧、关于你的一切 |
1. 数据的采集
我们主要分析两种数据
业务数据
简单的来说就是开发的内容中涉及的数据(站在开发者的角度来看)
行为数据
通过埋点收集和客户端产品交互过程中产生的数据(比如用户的点赞、收藏,评论、停留)
1 | 本项目收集和分析的用户行为数据主要有页面浏览信息、动作记录(商品收藏、)、曝光记录、启动记录、错误记录 |
1.1 数据同步的方式
- 全量数据同步(DataX)
- 增量数据同步(Maxwell)
1.2 数据流转到kafka
主要是为了进行实时(数据的处理以毫秒为单位)的处理
什么样的数据需要流转到kafka呢?(增量数据)
- Maxwell
- Maxwell , mysql的实现原理
主从复制
读写分离
1 | mysql的数据放在文件中、从文件中查询速度肯定很慢,所有mysql把经常查询的一部分1内容放到内存中,走内存进行查询,速率肯定快。而内存中也分几部分,有写缓存、和读缓存,当进行查询的时候,优先从写缓存中进行查询、查不到在从读缓存中进行查询。(此时用户新增的一个流程是,先将新增的数据写入写缓存中,达到一定的阈值之后写入文件,但此时出现一个问题,假如在向写缓存中的时候服务器突然挂掉、缓存中的数据就会丢失,这个时候就出现了数据丢失的问题)解决问题的方法:在写入缓存中先顺写到一个文件中、然后在向缓存中进行写入即可(注意:mysql在存储的时候是随机读写,效率不高,先写入一个文件,再写入缓存中是顺写,效率高)所以提高mysql的效率的一种方式就是使用更好的磁盘。同时还可以使用集群,而使用集群大致过程就是。向主节点进行写入,主节点将数据同步给集群中的其他节点(从节点),进行查询的时候只从从节点就行查询。这样保证了每台服务器职能比较单一,效率更好。而从节点进行数据同步的方式就是读取我们刚刚顺写的日志就可以保证从节点的数据同步了。 |
1.3 两种数据同步的方式
- 全量数据–也可以使用maxwell进行同步
- 增量数据-使用maxwell进行同步
1.4 hive分区的目的
- 提高查询效率 – 假如根据首字母进行分区,查找张三,只需要查找z开头的文件夹即可
- 一般分区按照天来进行统计
1.5 业务数据采集-零点漂移问题
出现在:将kafka中的数据通过flume同步给hdfs,然后给hive的过程中
1 | 使用拦截器进行解决: |
1.6 全量数据同步-DataX


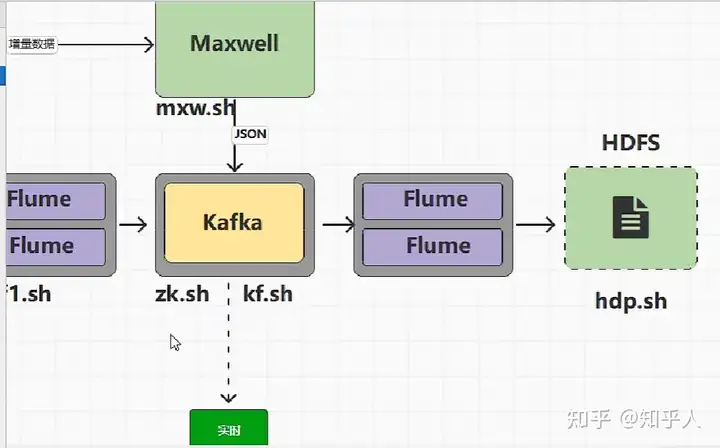
1.6.1 DataX使用案例




2. 数仓基础
2.1 数据仓库和数据库的区别
一:概念上来对别
- 数据仓库的数据,进行加工,然后对外提供服务
- 数据库主要在于存储,仓库主要在于进行打工,计算
二:数据来源对比
- 数据库的数据主要是企业中基础核心的业务数据
- 数据仓库的数据有部分是来自于数据库中
三:数据存储进行区分
- 数据库核心在于查找业务数据
- 数据仓库核心在于统计分析数据
四:数据价值进行区分
- 数据仓库:将统计分析结果为企业的经营决策提供数据支撑
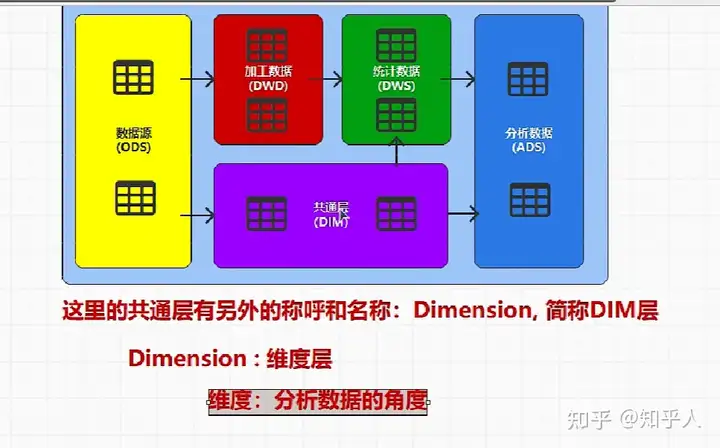
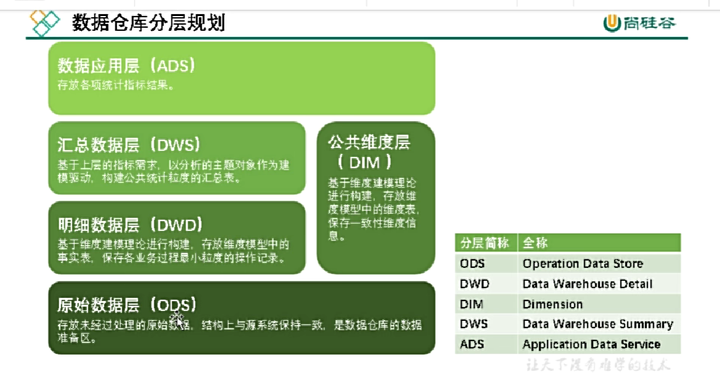
2.2 数据仓库内部结构-常见分层
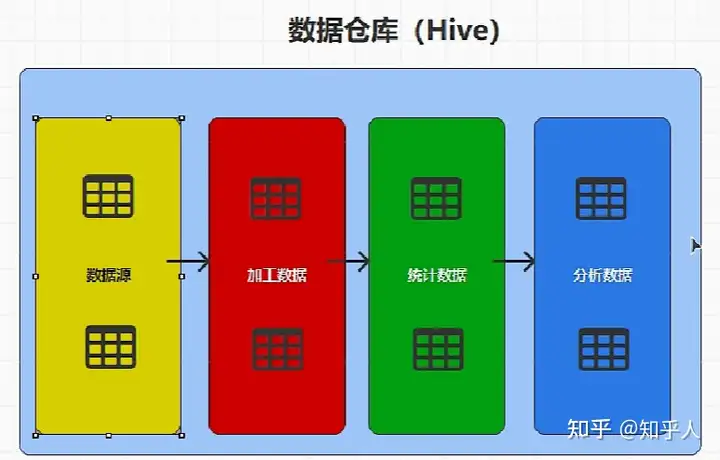
2.2.1 每层具体分析
- 数据源:对接日志服务器和业务数据库

- 加工数据:对ODS层的数据进行加工处理,为后面的统计分析做准备

- 统计数据

- 分析数据

- 共通层
- 任务调度器
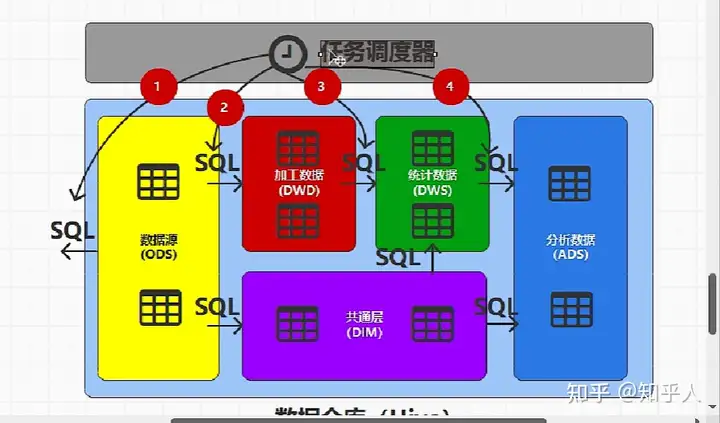
2.3 数仓项目学习重点
- 建表
- Sql
- 任务调度器
- 建表(建模)直接影响于SQL文的查询效率快慢与否
3. 数仓建模
3.1 方法论
1 | 1. ER模型 |
3.2 ER模型
对象关系
- 一对多
- 多对一
- 一对一
- 多对多
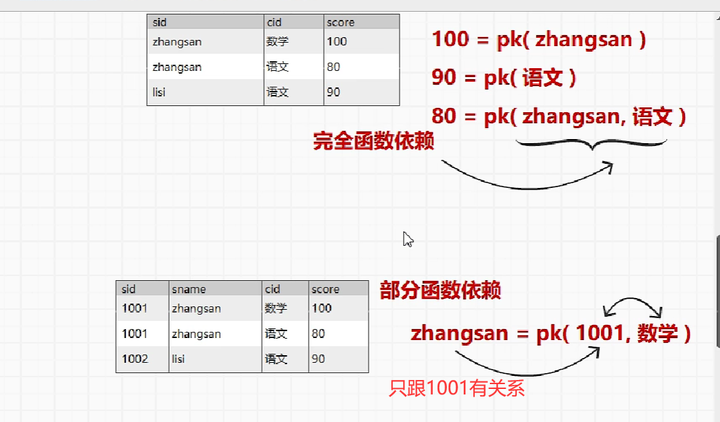
函数依赖关系
- 完全函数依赖 : 根据id,确定一个唯一的姓名
- 部分函数依赖 : 只需要传入的部分字段进行处理,就可以获得唯一的姓名(部分有用)
- 间接函数依赖 : 根据学生id,获取学生老师id,根据老师id获得老师姓名

范式理论(我们只针对前三范式进行说明-范式等级越高、数据冗余性低,但效率较低)
- 第一范式:属性不可切割
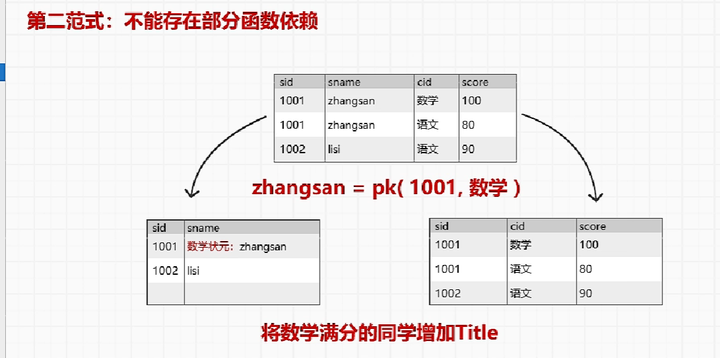
- 第二范式:不能存在部分函数依赖
- 第三范式:不能存在传递函数依赖


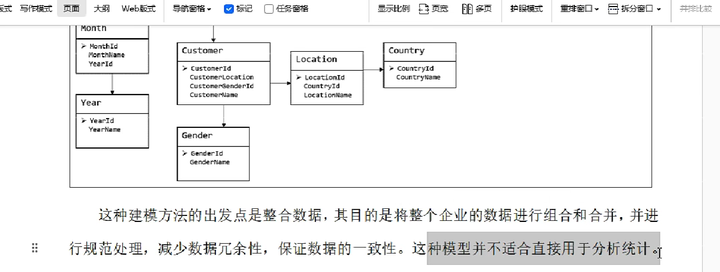
- ER模型的优缺点
ER模型不适合数仓仓库的建模操作
3.3 维度模型
核心:数据的分析统计
- 创建的表分为两大类:数据统计表(汇总什么样的数据)、数据分析表(从什么角度分析)
- 所谓维度就是分析数据的角度
4. 数仓运行环境
数仓构建流程
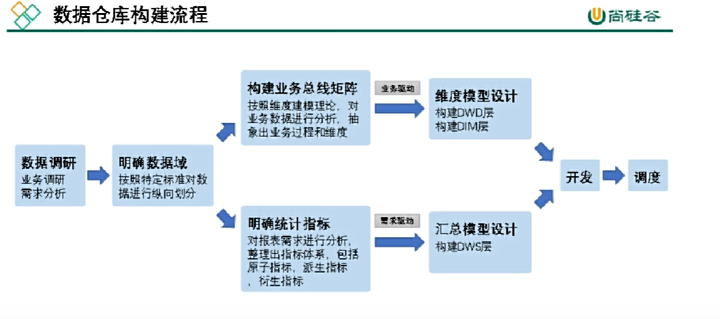
- 环境配置
- 我们使用的环境是Hive on Spark (谁在on前面,就是谁来解释sql文)
5. ODS层(数据源)开发
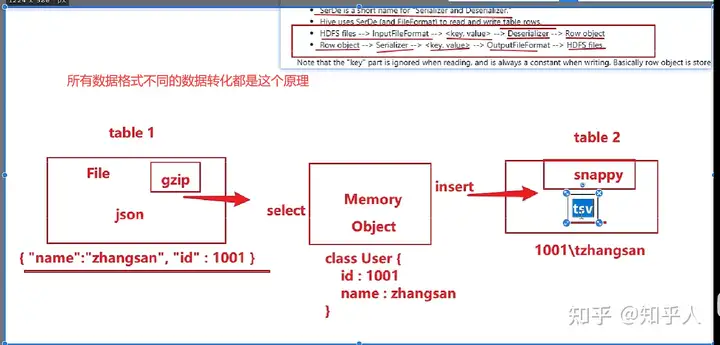
ODS层是ER模型,因为mysql是ER模型(实体、关系)数据格式尽可能不变
压缩格式尽可能不变
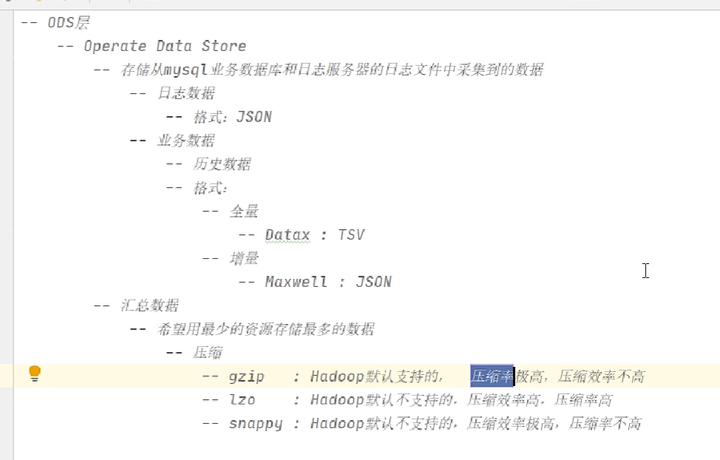


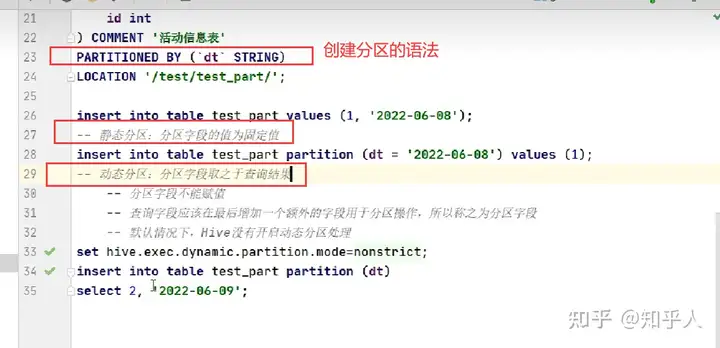
5.1 Hive分区扩展

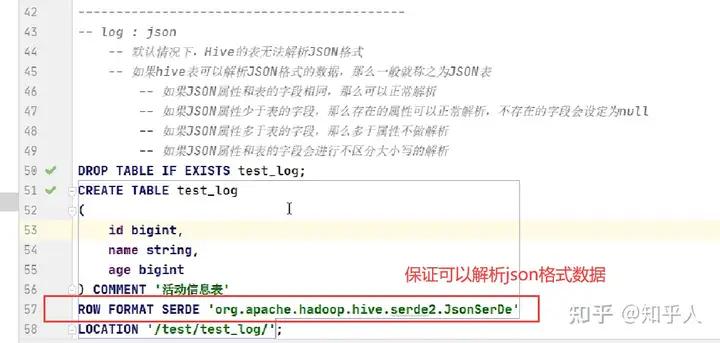
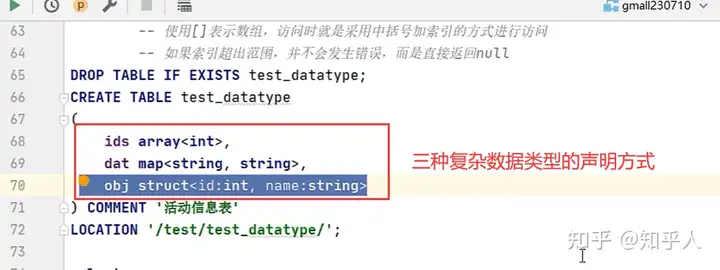
5.2 Hive复杂数据类型
1 | 对于JSON数据,一般将最外层的JSON对象的属性作为JSON表的字段,然后里面使用复杂数据类型作为值,同时map,和struct的区别在于,map一般用于key,value里面类型一样的才可以使用map,struct里面的属性和值的类型可以不尽相同 |
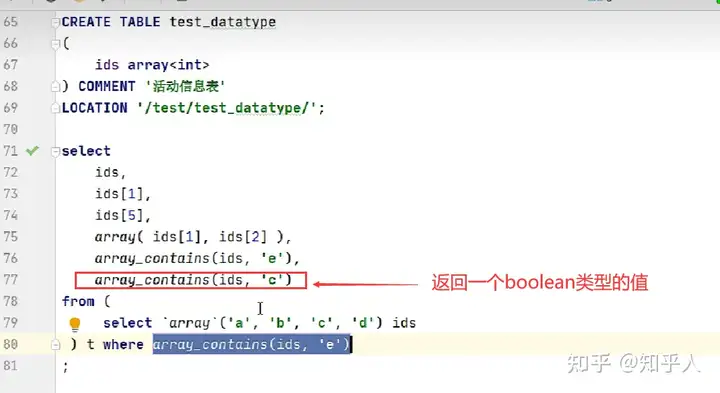
1. Array类型
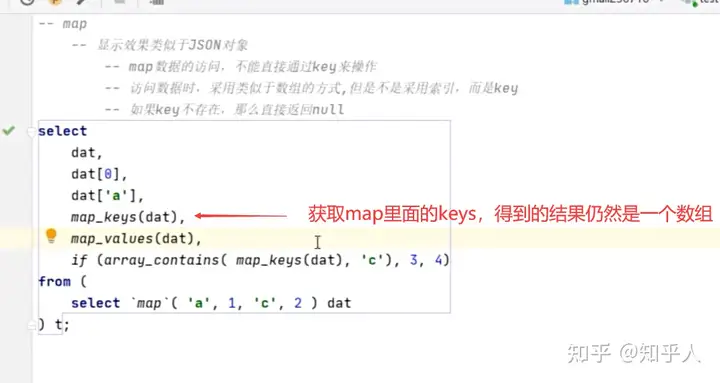
2. Map类型
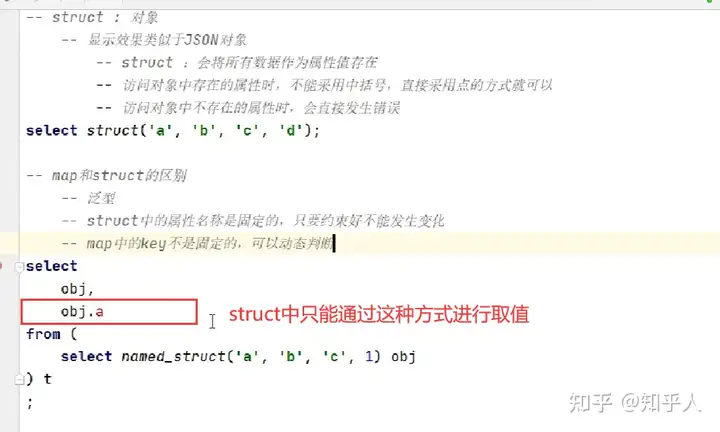
3. struct类型
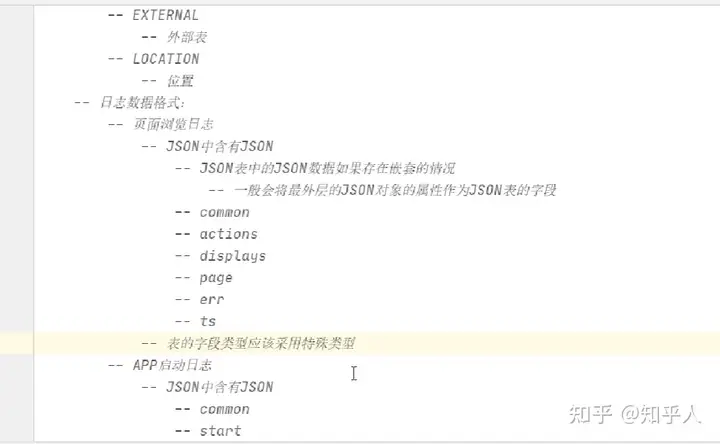
5.3 日志数据同步

5.4 业务数据同步
全量表
TSV格式DataX- 表结构和业务表保持一致即可
增量表
JSON格式Maxwell- 对象最外层的属性作为表的字段
使用脚本将数据进行批量导入
6. DIM层开发(共同维度层)
- 维度(状态)表
- 事实(行为)表




1 | 1.查询结果封装成指定属性的结构体,并且放到一个数组(返回一个数组类型,数组存放结构体) |

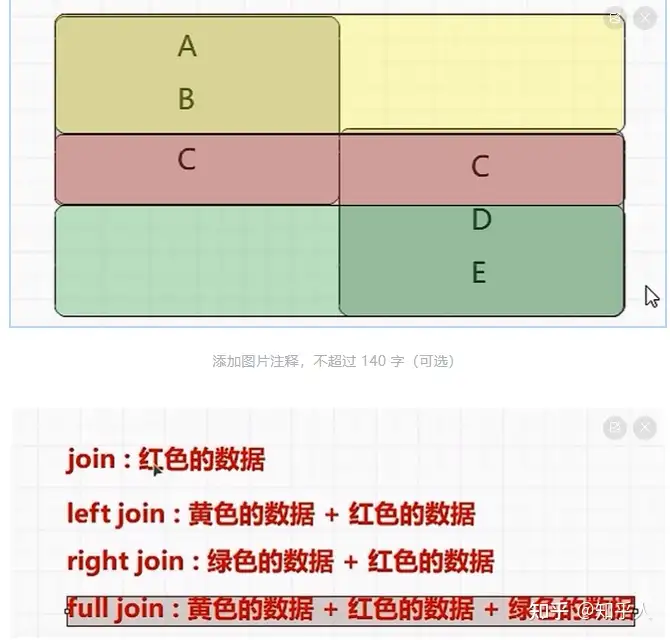
1 | 2. 表查询的几个关联操作(针对列) |
- Title: 数仓项目
- Author: Mr.zh
- Created at : 2024-04-16 17:08:22
- Updated at : 2024-04-29 14:46:46
- Link: https://github.com/zhyoulove/2024/04/16/数仓项目/
- License: This work is licensed under CC BY-NC-SA 4.0.