Spark SQL
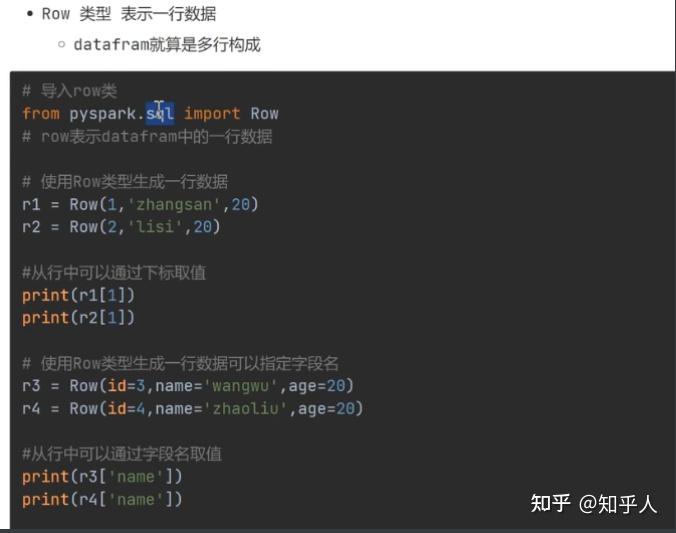
1. dataframe类型的详解

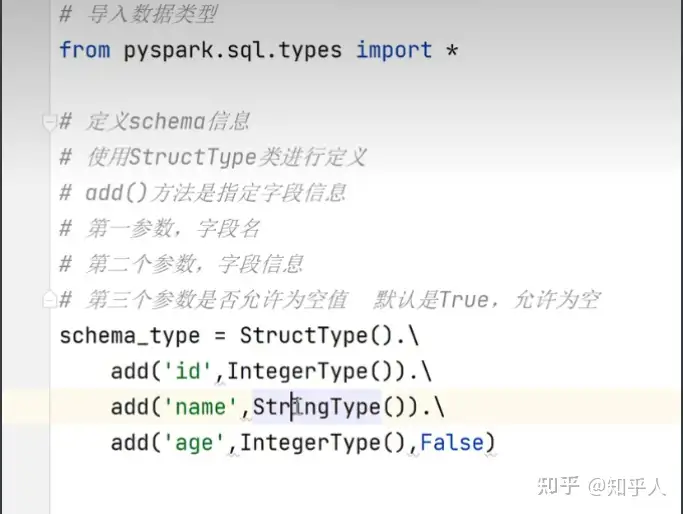
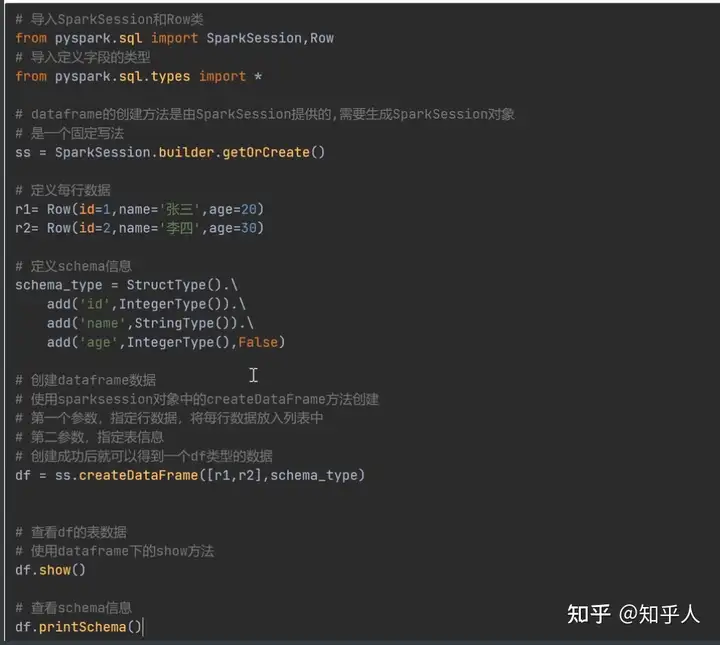
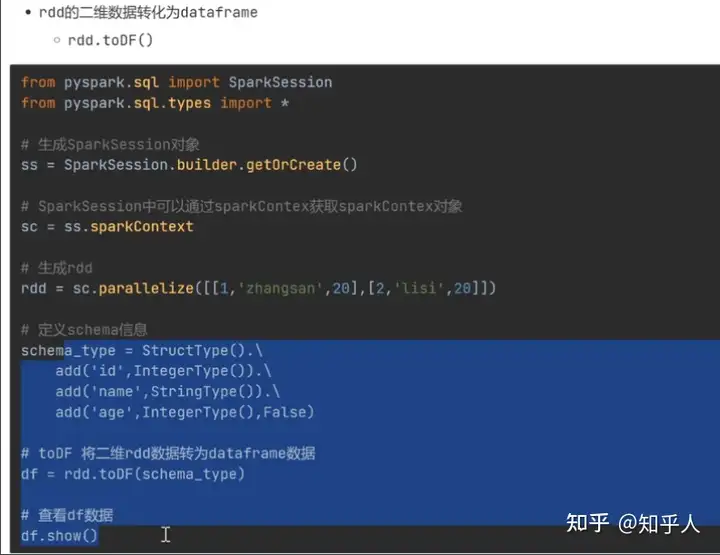
2. dataframe的创建
3. dataframe的使用
3.1 使用df中的方法进行操作(dsl方法 — df提供)
1
2
3
4
5
6
7
8
9
10
| df数据的查询
1. 指定查询的字段数据(指定字段的字符串格式,结果会返回一个新的df,可以使用df.show()查看
df.select('name')
2. 指定多个字段
df.select(['name','age'])
3. 直接使用df进行查询
df.select(df['name'],df['age'])
4. 展示所有数据
df.show() # 此时就是对所有字段进行处理
5. df.show(num) 可以指定展示多少条数据,默认是20条数据,同时show()方法不会返回新的df
|
1
2
3
4
5
6
7
| df的条件过滤
1. df.where('age > 20') # 相当于将所有数据都进行过滤,返回一个新的df
2. df.where('age > 20') # 相当于将所有数据都进行过滤,返回一个新的df,并且,没有指定行
相当于得到年龄大于20的全部过滤出来
3. 多个条件的与或非(and , or , )
df.where('age >= 20 and gender = "男"') # 注意单双引号的嵌套使用
|
1
2
3
4
5
6
7
8
| group by(分组操作,一般结合聚合操作)的操作
1. df.groupby('gender').sum('age')
# 相当于对性别进行分组操作,同时对两个组中的年龄进行累加
# select gender , sum('age') from df group by gender
# 常见的聚合函数:sum(),avg() , min() , max()
2. 对于多个分组字段的使用,和进行查询的时候一样,使用一个列表进行
# 相当于先对性别进行一个分组,然后在两个性别中在对每一个科目在进行一个分组
df.groupby(['gender , cls']).avg('age')
|
1
2
3
| 分组后的数据过滤
1. # 注意的点就是分组后的过滤,也不需要使用having,而是同样使用where
df.groupby('gender').sum('age').where('sum(age) > 80')
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| 排序操作 orderBy()
1. df.orderBy('age')
# 默认是升序排序,按照年龄进行升序排序
# 返回一个新的df
# 如果需要降序,就传入一个参数,进行降序排序
df.orderBy('age',ascending = False)
2. 多字段排序
# 如果需要多个字段进行排序,可以使用列表
# 先按照age进行排序,如果年龄相同,就按照id进行从小到大进行排序
df.orderBy(['age','id'])
3. (多字段是按照一个排序规则进行操作)
注意点就是,不能指定一个字段进行升序,一个降序。也就是说,和sql里面是一样的。
|
1
2
3
4
5
| 指定返回数量 limit()
1. # 返回指定数量的数据
# 返回一个新的df
df.limit(5)
|
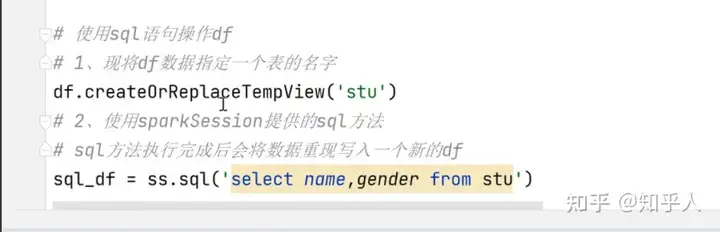
3.2 使用sql语句进行操作(sql语句—sparkSession提供)
3.3 关联的操作
1
2
3
4
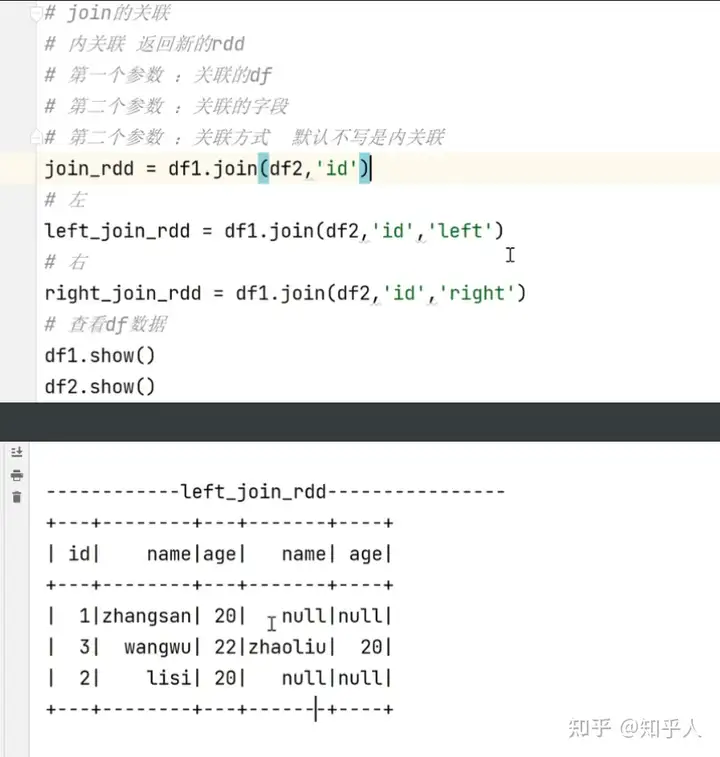
| join的关联操作
1. 内关联
2. 左关联 : 左边的数据全部展示,如果有相同的id,右边表的数据也会展示
3. 右关联
|
3.4 df数据的缓存和checkpoint
1
2
3
4
5
6
|
df.persist()
new_df = df.where('id > 1')
|
1
2
3
4
5
6
7
8
|
sc.setCheckpointDir('hdfs:///spark_checkpoint')
df.checkpoint()
|
- 当存在缓存和checkpoint时候,优先读取缓存中的数据,因为缓存的读写速度较快
3.5 df中的内置函数
spark中的内置函数和hive中的内置函数基本一致
使用之前需要导入相应的模块
1
2
| from pyspark.sql import SparkSession,functions as F
|
1
2
3
4
5
6
7
8
9
10
|
new_df = df.select(F.concat('id','name'))
new_df.show()
new_df = df.select(F.concat_ws(',' , 'id' , 'name'))
new_df.show()
df.select(F.substring('name' , 1 , 4))
df.select(F.split('date' , '-'))
|
1
2
3
4
5
6
7
8
9
10
11
|
df.select(F.current_date())
df.select(F.current_timestamp())
df.select(F.unix_timestamp())
df.select(F.from_unixtime('unix_t' , format="yyyy-MM-dd HH:mm:ss"))
df.select(F.date_add('date' , 1))
df.select(F.date_add('date' , -1))
|
1
2
3
4
5
|
df.groupby('gender').agg(F.sum('age') , F.avg('age'))
df.groupby('gender').agg(F.sum() , F.round(F.avg('age') , 2))
|
1
2
3
|
df.groupby('gender').agg(F.sum().alias('总和') , F.round(F.avg('age') , 2).alias('平均值'))
|
3.6 SparkSession的说明
1
2
3
4
5
6
7
8
9
10
11
12
| from pyspark.sql import SparkSession
ss = SparkSession.builder.getOrCreate()
ss1 = SparkSession.builder.master('yarn').getOrCreate()
ss1 = SparkSession.builder.master('yarn').appName('yarn_sparkSql').getOrCreate()
ss1 = SparkSession.builder.master('yarn').config().getOrCreate()
|
4.小案例—电影数据统计分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
代码流程如下:
from pyspark.sql import SparkSession
from pyspark.sql.types import *
ss = SparkSession.builder.getOrCreate()
sc = ss.sparkContext
rdd = sc.textFile('hdfs:///movie')
print(rdd.take(20))
table_rdd = rdd.map(
lambda x : [int(x.split('\t')[0]) , int(x.split('\t')[1]) , double(x.split('\t')[2]) ,s.split('\t')[3] ]
)
schema_type = StructType()
.add('userId',IntegerType())
.add('movieId',IntegerType())
.add('score',DoubleType())
.add('unix_time',StringType())
df = table_rdd.toDF(schema_type)
df.show()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
user_avg = df.groupBy('userId').agg(F.avg('score').alias('avg_data'))
user_avg.show()
movie_avg = df.groupBy('movieId').agg(F.avg('score').alias('avg_data'))
movie_avg= df.groupBy('movieId').agg(F.round(F.avg('score'),2).alias('avg_data'))
movie_avg.show()
3.1 : 得到不同用户打高分电影的数量
df.where('score >3').groupBy('userId')
.agg(F.count('movieId').alias('count_data'))
3.2 :然后根据数量进行降序排序,得到第一个就是打分次数最多的用户
df.where('score >3').groupBy('userId')
.agg(F.count('movieId').alias('count_data'))
.orderBy('count_data',ascending = False)
3.3 :first()方法,取出第一行数据
first()取出的是一个row对象,不在是一个df对象,不能使用show()进行展示哦
user_rdd = df.where('score >3').groupBy('userId')
.agg(F.count('movieId').alias('count_data'))
.orderBy('count_data',ascending = False).first()
print(user_rdd)
userId = user_rdd['userId']
print(user_rdd['userId'])
3.4 : 根据用户id查找这个用户所有打分电影的平均分:
user_movie_avg = df.groupBy('userId').agg(F.avg('score').alias('avg_data'))
user_movie_avg = movie_avg.where(movie_avg['userId'] == userId)
user_movie_avg.show()
|
1
2
3
|
df.groupBy('userId').agg(F.avg('score') , F.max('score') , F.min('score'))
|
1
2
3
4
5
|
df.groupBy('movieId')
.agg(F.count('movieId').alias('count_data') , F.avg('score').alias('avg_data'))
.where('count_data > 100')
.orderBy('avg_data',ascending = False).limit(10)
|
5. 分区数目(了解)
1
2
3
4
|
ss = SparkSession.builder.master('yarn')
.config('spark.sql.shuffle.partitions','6')
.getOrCreate()
|
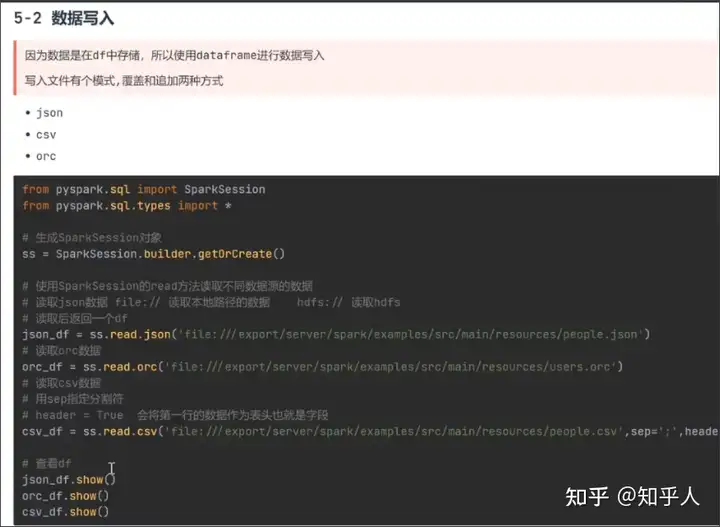
6. sparkSession读取不同类型文件
6.1 数据读入
注意在读取mysql的数据时候,需要将驱动依赖放到spark/jars/下
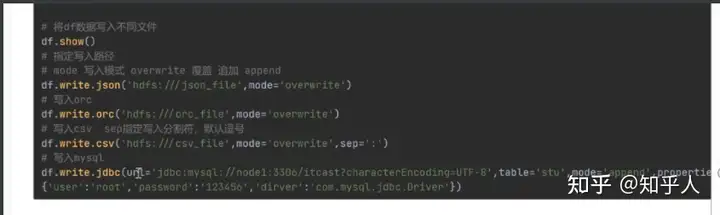
6.2 数据读出
7. 自定义函数
7.1 函数分类
- udf 一进一出 可以自定义
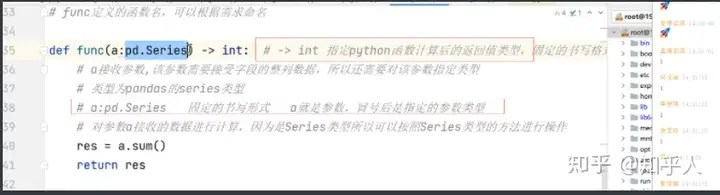
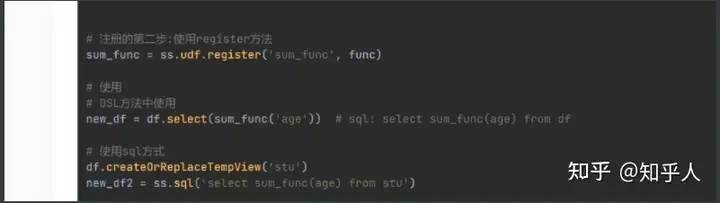
- udaf 多进一出 可以自定义 需要借助pandas
- udtf 一进多出 不能自定义
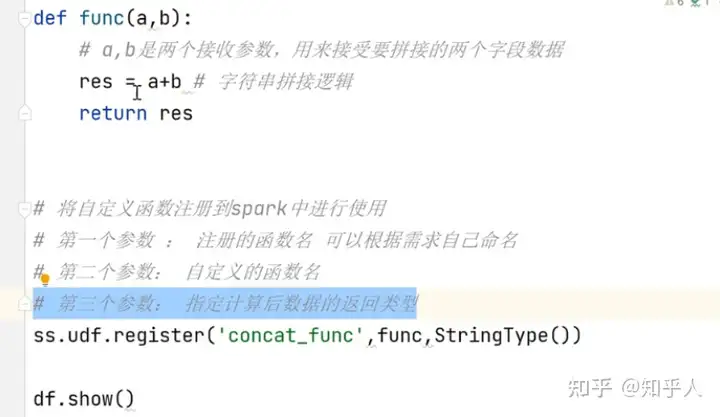
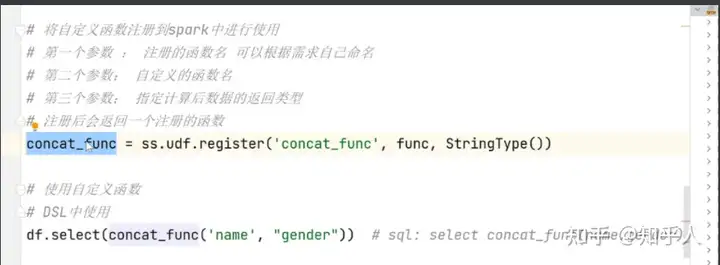
- 自定义udf函数步骤
- 数据是一行一行处理(传递一行处理一行)
- 自定义udf函数也可以使用sql语句的方式进行使用哦
自定义udaf函数步骤
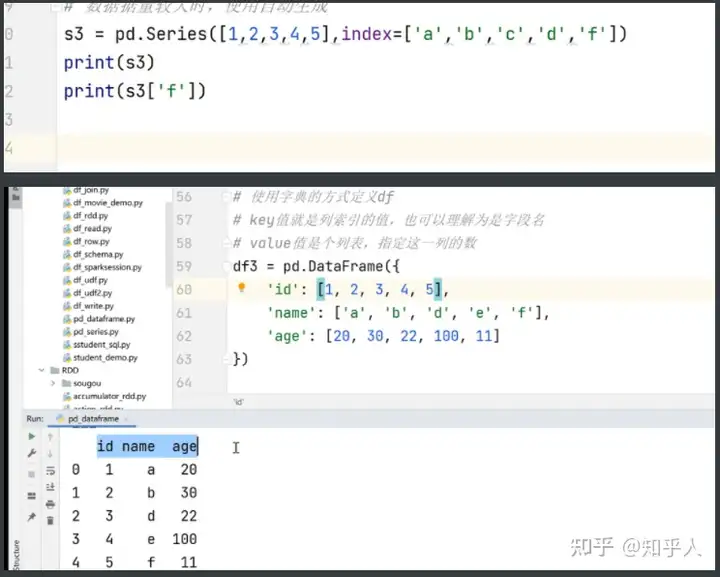
8.pandas的学习
定义方式(两种):
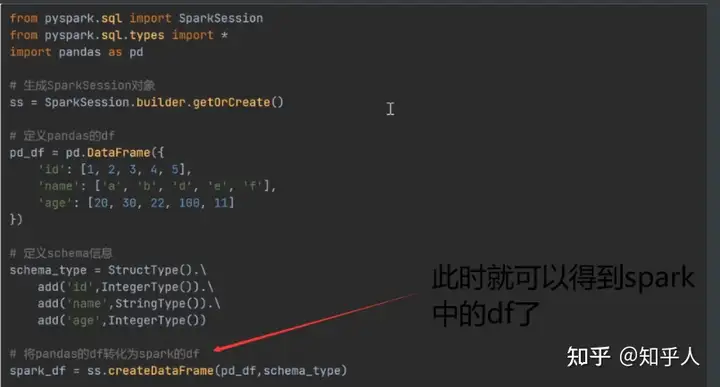
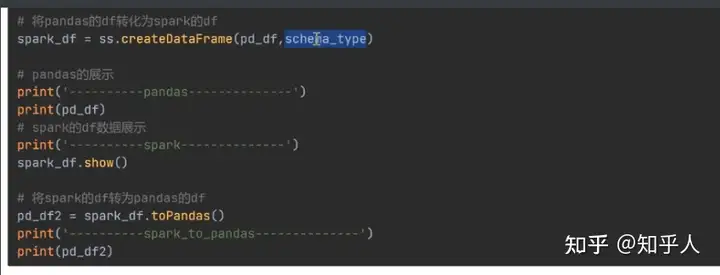
将pandas中的df转化为spark中的df进行计算