数据库-SQL
1. 杂七杂八
测试图片上传服务器功能
1 | 老身今自由。心无疚,随意度春秋 |
1.爆炸函数
使用爆炸函数可以将数组转化为一列数据
1
2
3
4
5
6select array(1,2,3,4)
select explode(array(1,2,3,4))
select sequence(1,100); -- 生成1到100,数组数据
# 配合爆炸函数快速生成一列数据
select explode(sequence(1,100)) as id -- 可以生成一列从1,到100的数组快速生成表的数据
1
2
3
4
5
6
7
8
9
10
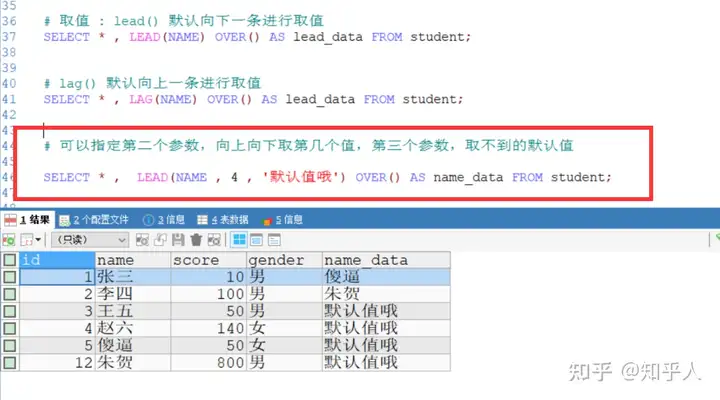
11select stack(
2, -- 这个参数指定表中有几条数据
1,'张三',23,
2,'李四',22 -- 这两行指定表的数据内容
);
# 也可以指定表中每一列的字段名称
select stack(
2, -- 这个参数指定表中有几条数据
1,'张三',23,
2,'李四',22 -- 这两行指定表的数据内容
) as (id , name , age);操作生成表的数据的方式

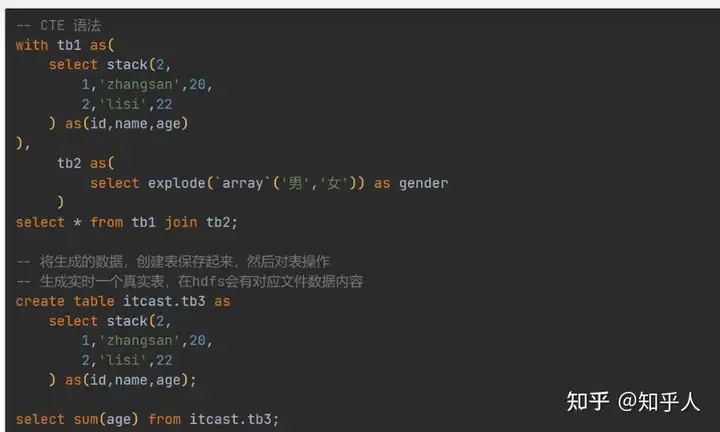
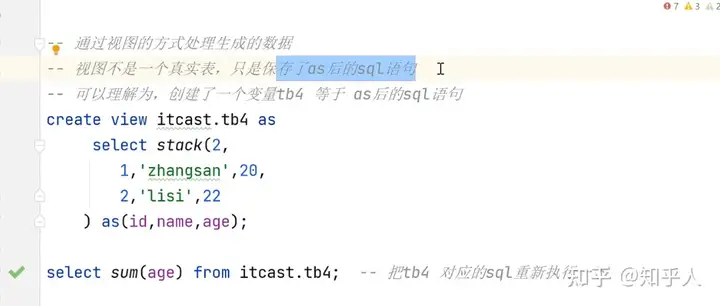

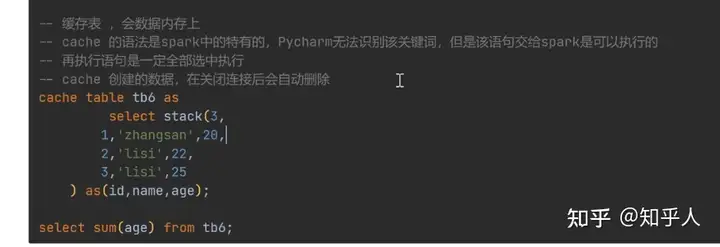
2.SparkSQL的执行引擎
- 解析器 : 将sql语句转化为语法树
- 分析器 : 语法树中被查询的字段数据类型-读取元数据声明被查询的字段类型
- 优化器 : 将语法树进行优化
- 谓词下推 : 比如先进行where的过滤条件,将过滤结果在进行join操作
- 列值裁减 : 只查询需要的字段
- 执行器 : 将最终语法树转化为rdd,交给spark进行最终执行
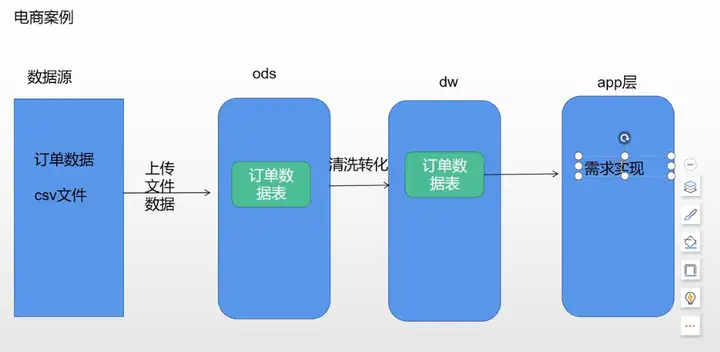
3. 电商案例
- 订单表字段说明
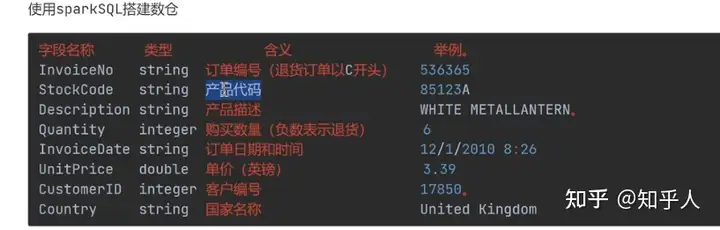
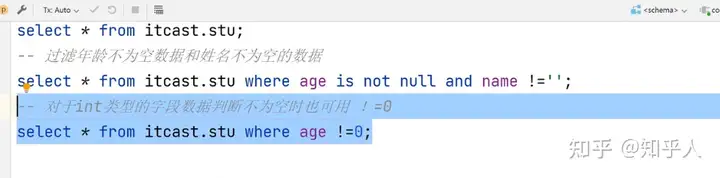
- 对原数据进行数据清洗的时候假如存在int类型和string类型的空,过滤方法为:
1 | # 注意点就是对于字符串过滤的时候,不能使用is not null 因为他不是null,是空字符 |
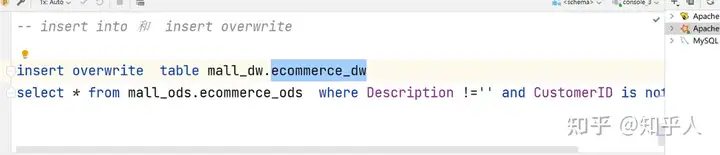
1 | # 然后将过滤之后的数据导入到下一层里面 |
- app层的计算指标
1 | # 1.销量最高的10个国家 |
1 | # 5. 退货订单数最多的10个国家 -- 求的是数量啊--使用内置函数--count() |
4. 消息队列(MQ)
1 | 突然有一天你会发现,你的思念不会因为长时间的不联系而消失,只会随着时间的流逝像野草般疯狂生长。 |
- 作用
- 进行实时计算需要
- 应用耦合 – 解耦 – 使用消息队列解耦
- 异步处理
- 限流削峰
- 消息队列的两种模式
- 点对点
- 发布与订阅
2. 数据库相关
1. 数据库-事务
事务是一组操作的集合,这组操作,要么全部执行成功,要么全部执行失败。
mysql的事务默认是自动提交,一条语句执行之后就自动提交了
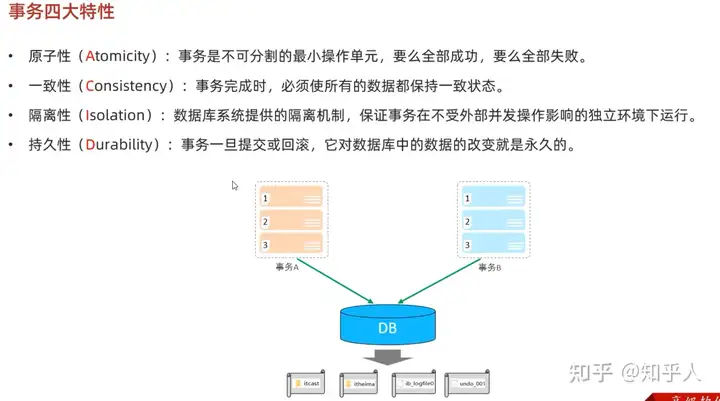
1.1 事务的四大特性
- 原子性
- 一致性
- 隔离性
- 持久性
1.2 并发事务问题
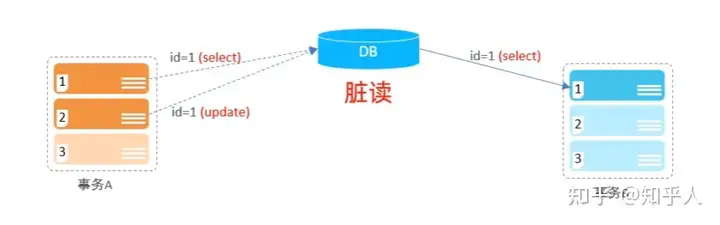
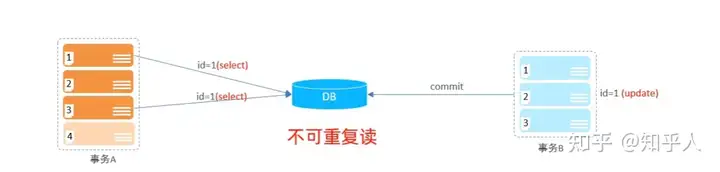
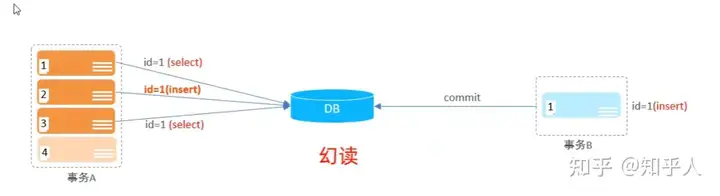
多个并发事务在执行的过程当中出现的问题
- 脏读
- 不可重复读
- 幻读

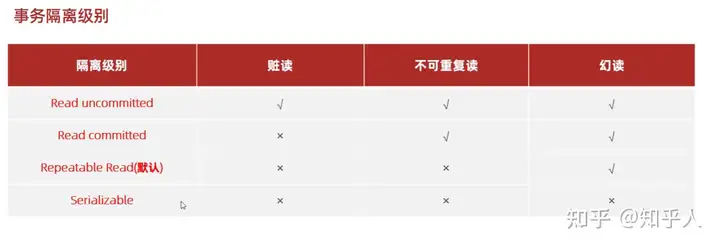
1.2.1 如何解决
通过事务不同的隔离级别进行解决(级别越高数据越安全、但效率越低)
2. 数据库-存储引擎
2.1 mysql的四大体系结构

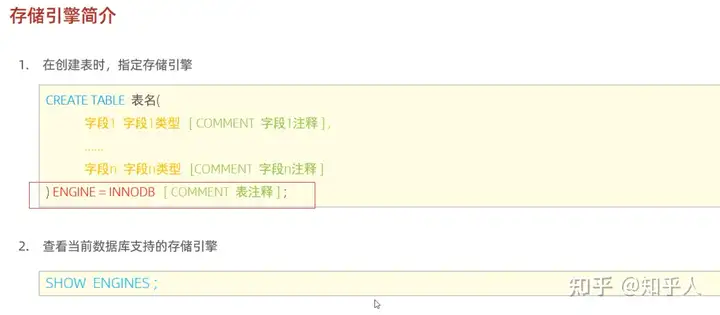
2.2 mysql的存储引擎
1 | 1. 存储引擎是基于表的,一个数据库下的不同表,可以有不同的存储引擎 |
- 如何使用
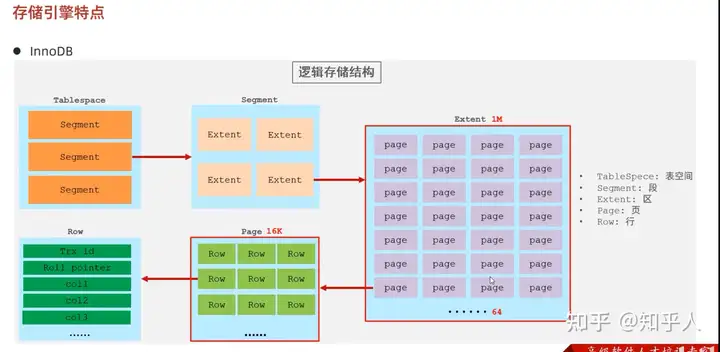
2.3 存储引擎的主要特点



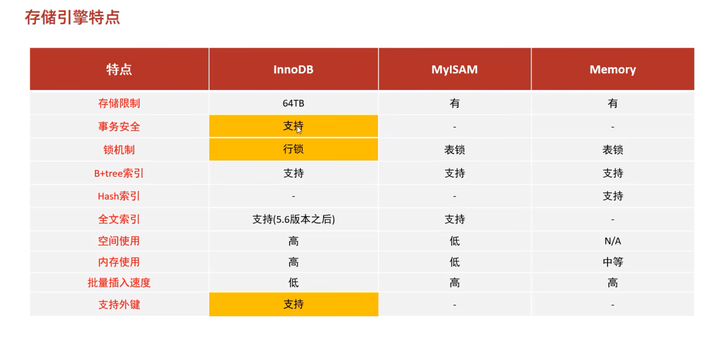
2. 4 面试题:InnoDB和MyISAM区别
问InnoDB和MyISAM的区别?(两个存储引擎的区别)
1 | InnoDB:支持事务、行锁、支持外键 |
2.5 存储引擎如何选择
1 | 根据系统应用特点,选择合适的存储引擎,一般用第一个,两外两个现在一般被MongoDB、redis代替 |

2.6 总结

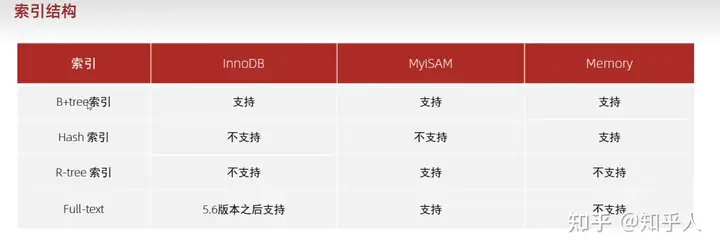
3. 数据库-索引
3.1 索引概述

优缺点

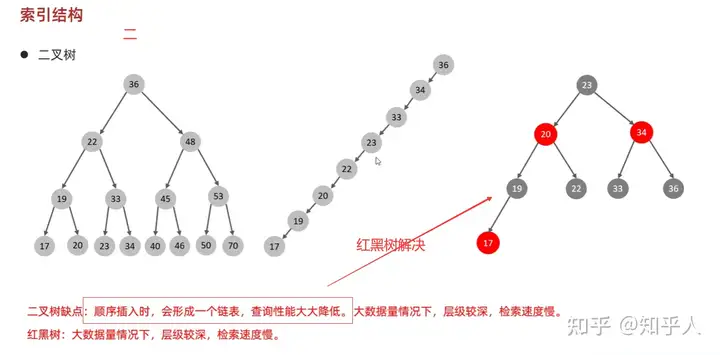
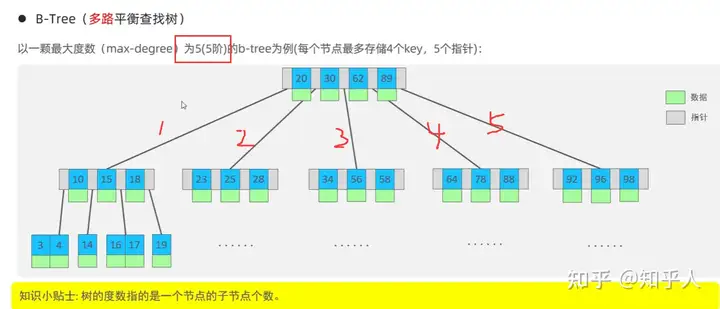
3.2 索引结构-B+树

- 二叉树(二叉搜索树)和红黑树(自平衡的二叉搜索树)
- B树(多路平衡搜索树)
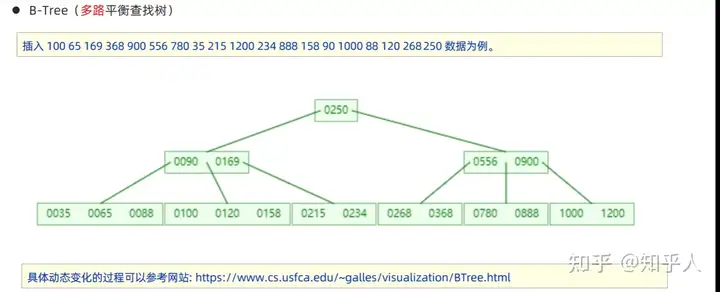
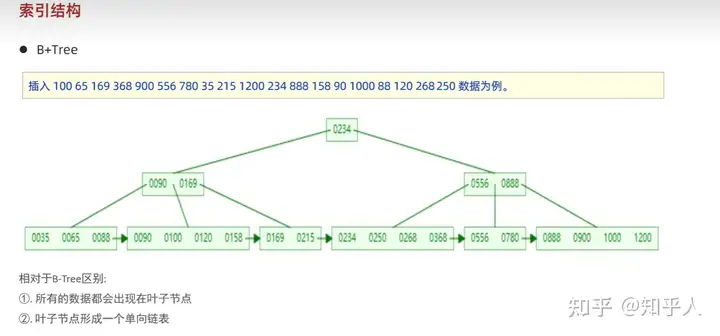
- mysql中优化后的B+树
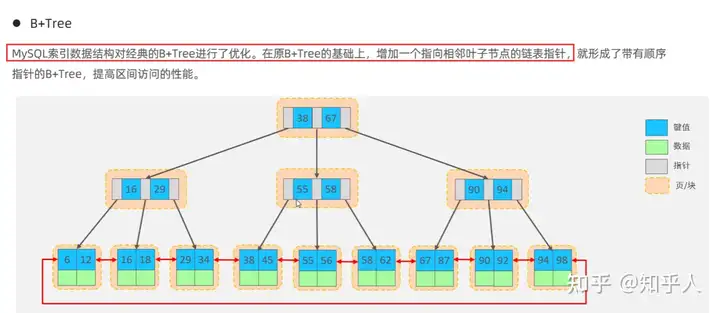
3.3 索引结构-Hash索引
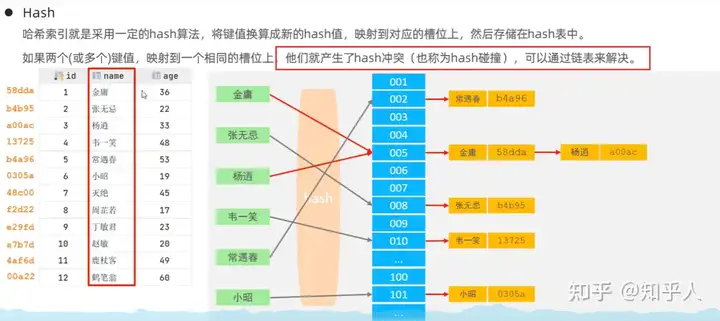

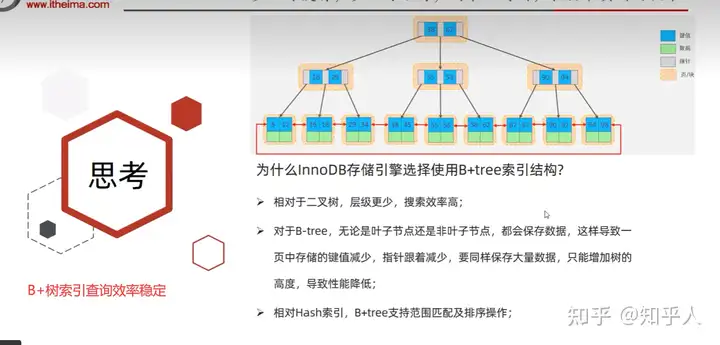
3.4 面试题:存储引擎为啥B+树
3.5 索引分类
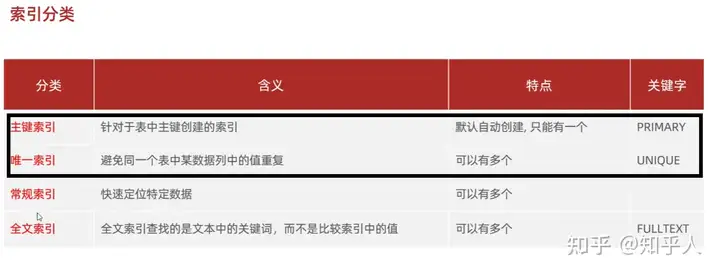

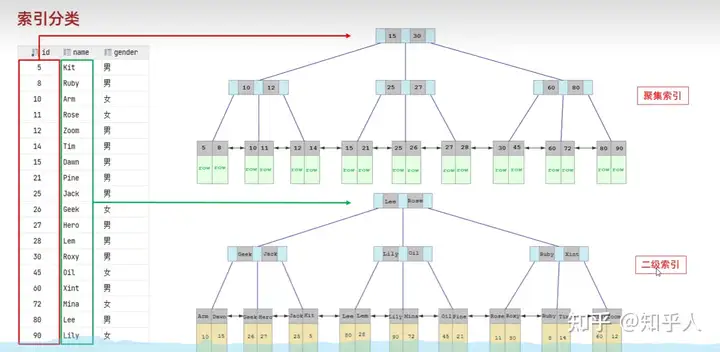
- 举例使用-回表查询
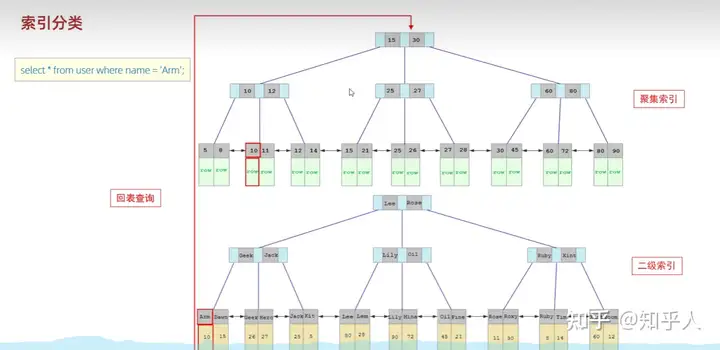
3.6 索引的使用
1. 创建索引
1 | -- 创建索引 : |
2. 查看索引
1 | -- 查看索引 |
3. 删除索引
1 | -- 删除索引 |
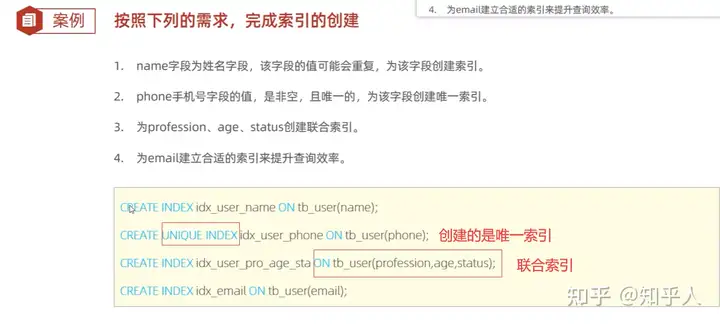
4. 索引小案例
3.7 Sql性能分析
1 | -- 1. sql执行频率 |
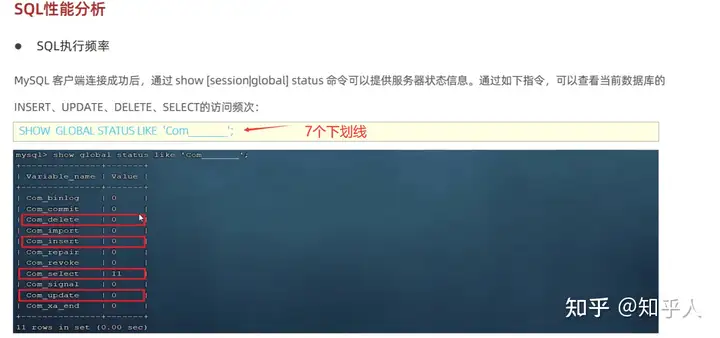

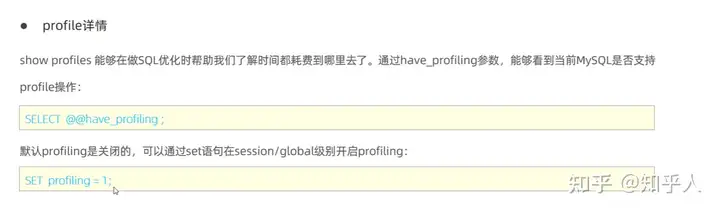
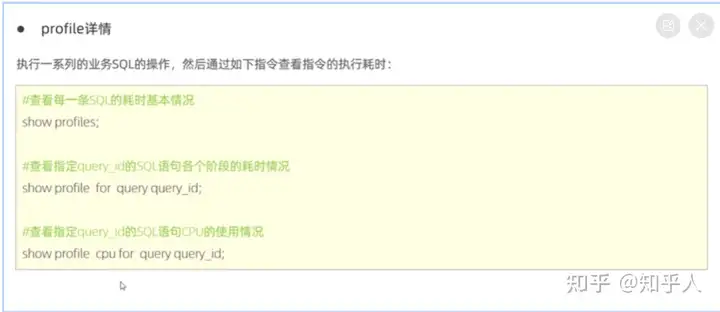
explain的相关使用和优化点



3.8 索引使用的特殊情况
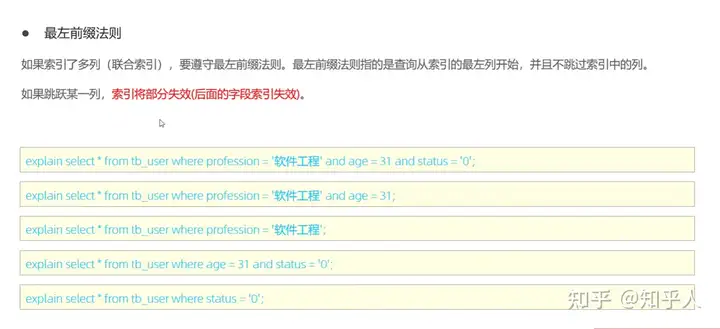

索引失效的几种情况:

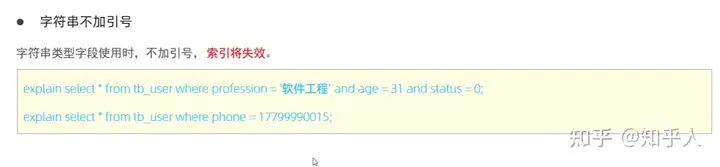
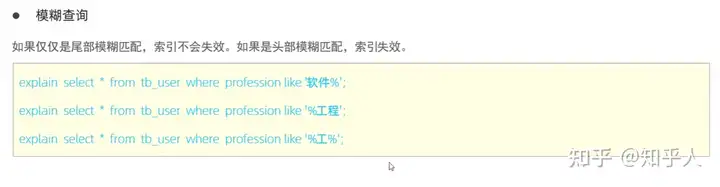
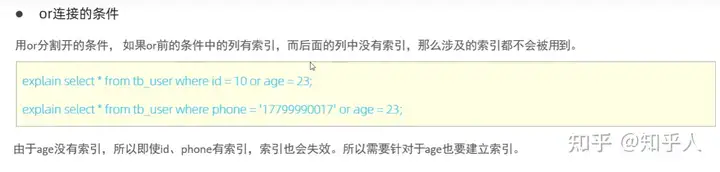

- Sql提示

- 覆盖索引
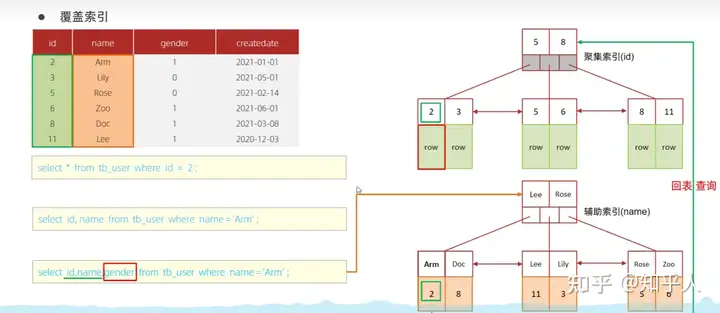
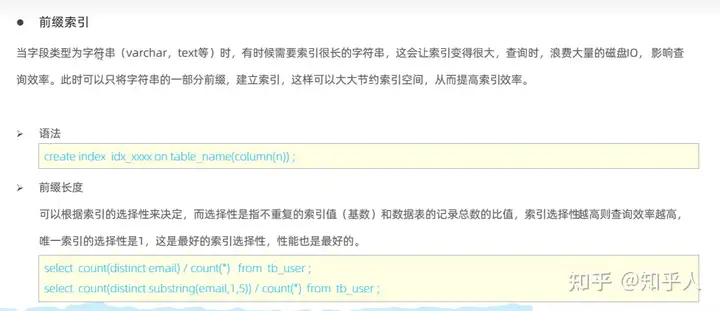
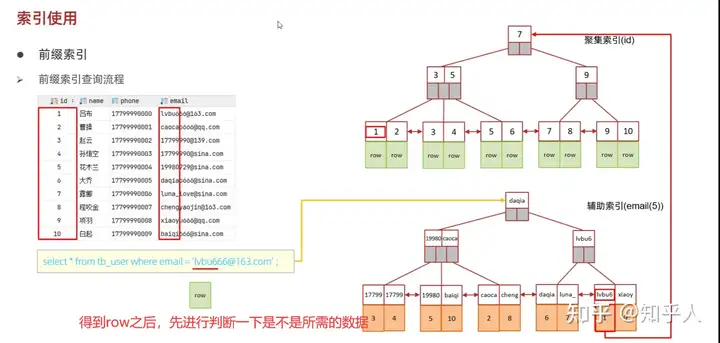
- 前缀索引
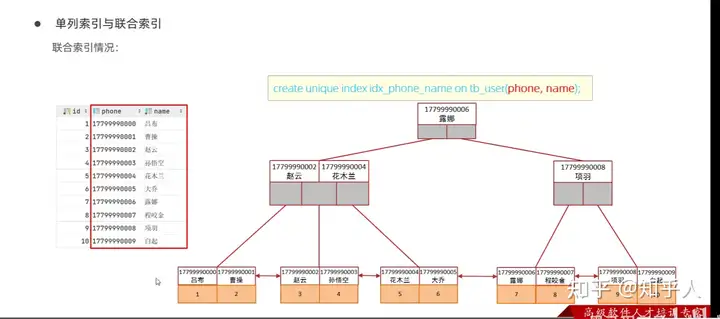
- 单列/联合索引
- 索引设计原则

3.9 索引总结


4. sql优化
1. 插入优化
- 批量插入
- 手动提交事务
- 按照主键顺序插入
- 对于大批量插入数据不能使用insert,使用load进行加载插入
2. 主键优化
- 主机顺序插入的效率高,在于不发生页分裂。也就是主键乱序插入的时候,可以发生页分裂
1 |
- 页分裂-页合并:当某一页中的数据小于一个值(默认50%)就有可能发生页合并
主键设计原则:
1. 尽可能将主键字段设计较短(二级索引存储的是主键,占内存)
1. 尽量选择主键顺序插入
1. 避免使用uuid,身份证号码等作为主键
1. 业务操作,尽量避免对主键的修改
3. order by优化
-
4. group by优化
5. limit优化
6. count优化
7. update优化
- Title: 数据库-SQL
- Author: Mr.zh
- Created at : 2024-04-10 19:50:12
- Updated at : 2024-05-17 22:34:17
- Link: https://github.com/zhyoulove/2024/04/10/数据库-SQL/
- License: This work is licensed under CC BY-NC-SA 4.0.