Java刷题技巧
刷题网站推荐
1 | 明确各个不同网站之间的区别:如力扣的代码是核心代码模式,而牛客等就是ACM模式,内容推荐系统刷力扣,针对练习洛谷、牛客中的难题,最后也可以多打打cf比赛 |
1.Arrays.sort自定义排序规则
1 | public int[][] reconstructQueue(int[][] people) { |
2.大顶堆小顶堆的数组存储特点
1 | 1. 为简化计算,堆进行存储的时候数组下标也可从1开始, |
例题:
1 | 代码答案如下: |
3. Java读取文件,暴力分割矩阵
1 | import java.io.*; |
4. Java算法模板
1 | // 求最大公约数模板 |
1 | // 分解质因数模板 -- 将一个数分解成诺干质数相乘 |
1 | // 判断一个数是不是质数模板 |
1 | // 快速幂 |
5. 回溯之切割问题
问题1 : 力扣131. 分割回文串
1 | 代码如下: |
问题2 力扣93. 复原 IP 地址
1 | 代码如下: |
6. Java中快速读写的代码
1 | import java.io.*; |
7. 指定字符数组长度转化为字符串
1 | // String.valueOf(char[] chars , 0 , num) 这个方法的作用就是将chars字符数组,从chars[0]开始,取长度为num个元素,转化为字符串 |
8. KMP算法模板
1 | public class Main1 { |
9. Java中大数的基本使用
1 | // 加减乘除取模运算 |
10 终要面对-Dijkstra算法
1 | 必要学会版 V1.0 |
GitHub源代码: https://github.com/yuanjiejiahui/Dijkstra
- 算法常用于处理单源出发到其他所有节点的最短路径问题,适用于不含有负权重的有向和无向图
- 算法采用贪心策略,具体代码借助堆来优化算法
1 | class Solution { |
11 多次见面-并查集
1 | 我是不想见你的,奈何多次要见 |
- 题单1-寻找图中是否存在路径
1 | class Solution { |
- 题单2-547. 省份数量
1 | class Solution { |
- 总结UF(并查集)模板
1 |
|
4 . LCR 118. 冗余连接
1 | 题目:在一个数中新添加了一条边,然后给你一个边的二维数组,请你求出,去掉哪一条边之后,仍然使得:剩余部分是一个有着 n 个节点的树(这一句话表示:删除一条边之后 , n个节点仍然是连通的)。如果有多个答案,则返回数组 edges 中最后出现的边。 |
1 | // 代码如下 |
12 再见深搜
1 | 最优解不是使用dfs,为复习dfs,选择dfs |
1 | static int[][] direction = {{0 , 1} , {1 , 0} , {1,1}}; |
13 龟兔赛跑算法–快慢指针的使用
1 | Floyd判圈算法 |
141. 环形链表 判断是否存在环
1 | public boolean hasCycle(ListNode head) { |
142. 环形链表 II 求环的起点
1 | public ListNode detectCycle(ListNode head) { |
对于求环的长度问题暂未遇到。思路是:假设存在环,快慢指针第一次相遇的位置一定在环的某个位置上,然后让快指针不动,慢指针走一圈,引入一个变量计算长度,当慢指针与快指针再次相遇的时候,刚好为环的长度。
14 Java数学类的三个方法
1 | 一定要注意,题目中要求的数据范围:是四舍五入,还是什么 |
- **Math.ceil(double a)**:向上取整方法。返回大于或等于参数的最小整数。如果参数是正数,则返回大于或等于该参数的最小整数;如果参数是负数,则返回小于或等于该参数的最大整数。返回值类型为
double。 - **Math.floor(double a)**:向下取整方法。返回小于或等于参数的最大整数。如果参数是正数,则返回不大于该参数的最大整数;如果参数是负数,则返回大于或等于该参数的最小整数。返回值类型为
double。 - **Math.round(float a) 和 Math.round(double a)**:四舍五入方法。返回最接近参数的整数。对于
float类型的参数,返回int类型的整数;对于double类型的参数,返回long类型的整数。这是标准的四舍五入操作,即如果待舍入数的小数部分大于等于0.5,则向上取整;如果小于0.5,则向下取整。
15 再学完美、完全二叉树
- 二叉树的性质
1 | (1)若二叉树的层次从0开始,则在二叉树的第i层至多有2^i个结点(i>=0)。 |
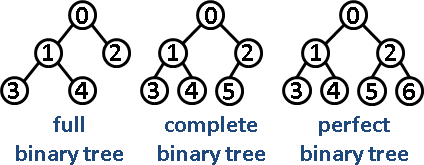
- 完美二叉树(满二叉树)
1 | 一个深度为k(>=-1)且有2^(k+1) - 1个结点的二叉树称为完美二叉树。 |
- 完全二叉树
1 | 完全二叉树从根结点到倒数第二层满足完美二叉树,最后一层可以不完全填充,其叶子结点都靠左对齐。 |
- 完满二叉树
1 | 所有非叶子结点的度都是2。(只要你有孩子,你就必然是有两个孩子。) |
- 完满(Full)二叉树 vs 完全(Complete)二叉树 vs 完美(Perfect)二叉树
1 | // 代码如下 |
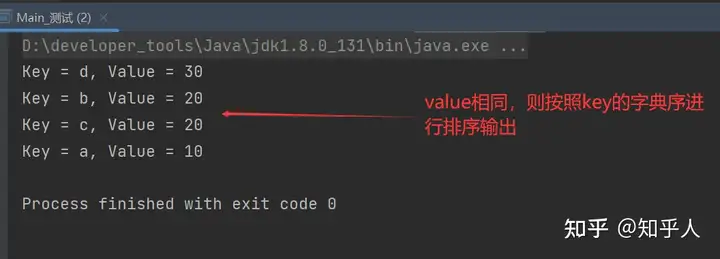
16 HashMap重写排序
1 | // HashMap 根据value进行排序 |
17. 位移运算符
1 | 1. 左移m<<n 代表把数字m在无溢出的前提下乘以2的n次方。 |
18. 无敌前缀树
1. 使用类的方式构建前缀树
1 | import java.util.HashMap; |
2. 使用静态变量的方式构建(推荐)
1 | static class Trie{ |
3. 相关题目讲解
1 | class Trie { |
19 .数论
1 | 前言:真心感慨先人的智慧,各种定理,各种推理,全部给出结论,而我在几十年后的今天看了好久才能看出一丝门道,学无止境啊 |
1. 费马小定理
1 | 1. 概念:如果p是一个质数,而整数a不是p的倍数,即a与p互质,那么满足等式a^(p-1)≡1(mod p),即a的(p-1)次方除以p的余数恒等于1 |
2. 快速求逆元
前提,p为质数
题目:
1 | 技巧1 : 0 异或 任意数 等于 任意数 |
- 注意这个和快速幂还有些不同,在利用下述模板进行逆元求解的时候,不要忘记模m了
1 | static long pow2(long x , long y , long m){ |
蓝桥真题
给定质数模数 M=2146516019M=2146516019,根据费马小定理对于不是 MM 倍数的正整数 aa,有 a(M−1)≡1(mod M)a(M−1)≡1(mod M),求出 [1,233333333][1,233333333] 内所有自然数的逆元。则所有逆元的异或和为多少?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- ```java
long res = 0;
long m = 2146516019;
for (int i = 1; i <= 233333333 ; i++) {
res ^= pow2(i , m - 2 , m);
}
System.out.println(res);
=============================================================================
static long pow2(long x , long y , long m){
long res = 1;
while (y != 0){
if (y % 2 == 1){
// 表示此时是奇数
res = res * x % m;
}
y = y/2;
x = x * x % m;
}
return res;
}
3. 数论
20 差分数组
1 | 对连续子数组的操作,可以转变为对差分数组中的两个数的操作 |
1. 定义和常用性质
1 | # 定义:对于数组a,他的差分数组d为: |
2. 例题
1 | class Solution { |
- Title: Java刷题技巧
- Author: Mr.zh
- Created at : 2024-04-01 21:50:32
- Updated at : 2024-05-26 23:55:53
- Link: https://github.com/zhyoulove/2024/04/01/Java刷题技术/
- License: This work is licensed under CC BY-NC-SA 4.0.